AI Agents: We Need Less Hype and More Reliability
 Adrian Krebs,Co-Founder & CEO of Kadoa
Adrian Krebs,Co-Founder & CEO of Kadoa2025 is supposed to be the year of agents, according to the big tech players. Cheaper models, more powerful tools (MCP, memory, RAG, etc.), and 10X inference speed are making agents better and more affordable. But what most customers are looking for isn't more capability, it's reliability.
We've deployed AI agents into production for some of the largest investment firms in the world. Here's what we've learned.
Less Hype, More Reliability
Most customers don't need shiny, complex AI systems. They need simple and reliable automations that solve one specific pain point exceptionally well. The "book a flight" agent demos are very far away from this reality.
Our AI agents for unstructured data are dead simple, but they solve real problems:
- Web monitoring: A market maker missed key market events due to slow, high-maintenance, rule-based scrapers. Our agents increased their monitoring coverage 5X with no maintenance.
- Web scraping: The data team at a leading hedge fund was overwhelmed maintaining hundreds of scrapers. Our agents cut their setup and maintenance workload by 85%.
- Company filings: A quant fund manually extracted data from complex filings, which took them weeks. Our agents automated this, delivering the data within a day.
Every data engineer we speak with is happy about offloading this kind of tedious data collection and cleansing work to AI agents, as long as the outputs are trusted and reliable.
This is why seemingly unexciting but business-critical tasks are where AI agents deliver the most value. Agents won't take any of our jobs, but they'll automate tedious, repetitive work like web scraping, form filling, and data entry.
Build vs. Buy
Many of our customers have tried building their own AI agents, but often struggled to reach the desired level of reliability.
The top reason in-house initiatives often fail is that building the agent is only 30% of the battle. Deployment and ensuring reliability at production scale are the hardest parts.
The problem shifts from "Can we extract the text from this document?" to "How do we teach an LLM to extract the data, validate the output, and confidently deploy it in production for 100,000 documents?" Achieving above 95% accuracy in real-world, complex use cases requires not only state-of-the-art LLMs, but also:
- Orchestration (parsing, classification, extraction, and splitting)
- Tooling that enables non-technical domain experts to quickly iterate, review results, and improve accuracy
- Comprehensive, automated data quality checks
Data Validation
In finance, there is virtually no room for data errors or hallucinations, especially when the data informs investment decisions. But the non-deterministic nature of LLMs makes it a challenge to ensure reliable and accurate data at scale.
We combine traditional checks with the contextual understanding of LLMs to ensure data quality:
- Rule-based checks: Applying traditional validation rules like regex patterns or value range checks.
- Reverse search: Verifying that output data was actually present in the raw input.
- LLM-as-a-Judge: Using LLMs to evaluate outputs against specific quality criteria (e.g., coherence, consistency, completeness) and business rules.
- Confidence scoring: Assigning confidence scores to outputs and flagging uncertain records for review.
- Human-in-the-loop: Allowing domain experts to easily review, correct, and approve outputs.
Compliance
Finance is a highly regulated industry, so AI agents must be integrated in a fully compliant manner. Firms can't just send their data to a foreign AI company and let them train models on it.
We invest considerable time in educating compliance departments, as it's a new concept for them that financial analysts can use AI agents in a fully self-serve manner. Previously, an engineer would code a bespoke data pipeline for each source and get case-by-case compliance approval. Now, even non-technical users can set up data workflows in minutes, so we need a new approach to compliance oversight.
Some key compliance controls we've implemented with our customers include:
- Configurable agent restrictions and compliance rules (e.g., defining what sources the agent can access)
- Detection of sensitive data (PII)
- Automated checking of robots.txt
- A compliance officer role to regularly pull audit reports of all activity
Zero data retention policies and a firm commitment to never using customer data for AI model training are non-negotiable requirements for all finance clients. Many new AI tools still lack these fundamental security and compliance mechanisms.
Outlook
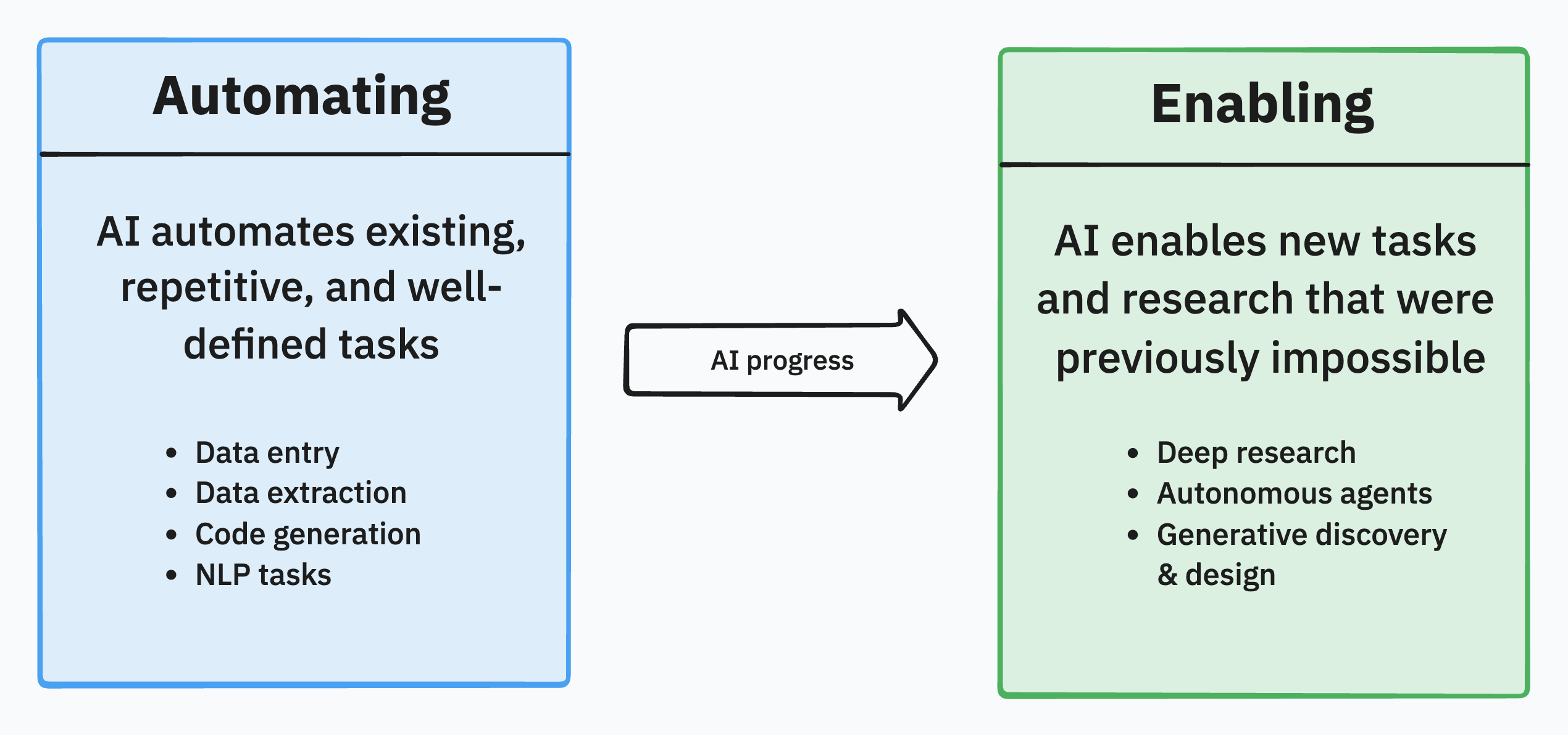
The demand for AI agents is surging, but many agents we see out there are optimized for flashiness, not results. Companies ultimately don't care about "AI", they care about ROI. That's why the current focus should be on automating well-defined tasks with highly reliable agents.
However, we should not narrowly see AI agents as replacing work that already gets done. Most AI agents will be used to automate tasks that humans with rule-based systems never got around to doing before because it was too expensive or time-consuming. This opens up entirely new opportunities for businesses.

Related Articles

Introducing Kadoa Assistant, powered by our Web Scraping OS
Announcing a fundamentally better way to extract web data

How AI Is Changing Web Scraping in 2026
Explore how AI is changing web scraping in 2026. From automation and data quality to compliance to scalability and real-world use cases.

The Top AI Web Scrapers of 2026: An Honest Review
In 2026, the best AI scrapers don't just write scripts for you; they fix them when they break. Read on for an honest assessment of the best AI web scrapers in 2026, including what they can and cannot do.