
Is fine-tuning LLMs still worth it in 2025?
 Adrian Krebs,Co-Founder & CEO of Kadoa
Adrian Krebs,Co-Founder & CEO of KadoaIs fine-tuning LLMs still worth it in 2025, even as foundational models advance so rapidly? For example, Bloomberg spent $10M training a GPT-3.5 class LLM on their financial data last year. Soon after, GPT-4-8k outperformed it on nearly all finance tasks.
This doesn't mean fine-tuning is obsolete. The answer, as with most things, is "it depends." Optimizing LLMs for accuracy requires using the right strategy based on your specific use case.
LLM Optimization Strategies
OpenAI has written a great overview of the two main strategies for optimizing LLMs:
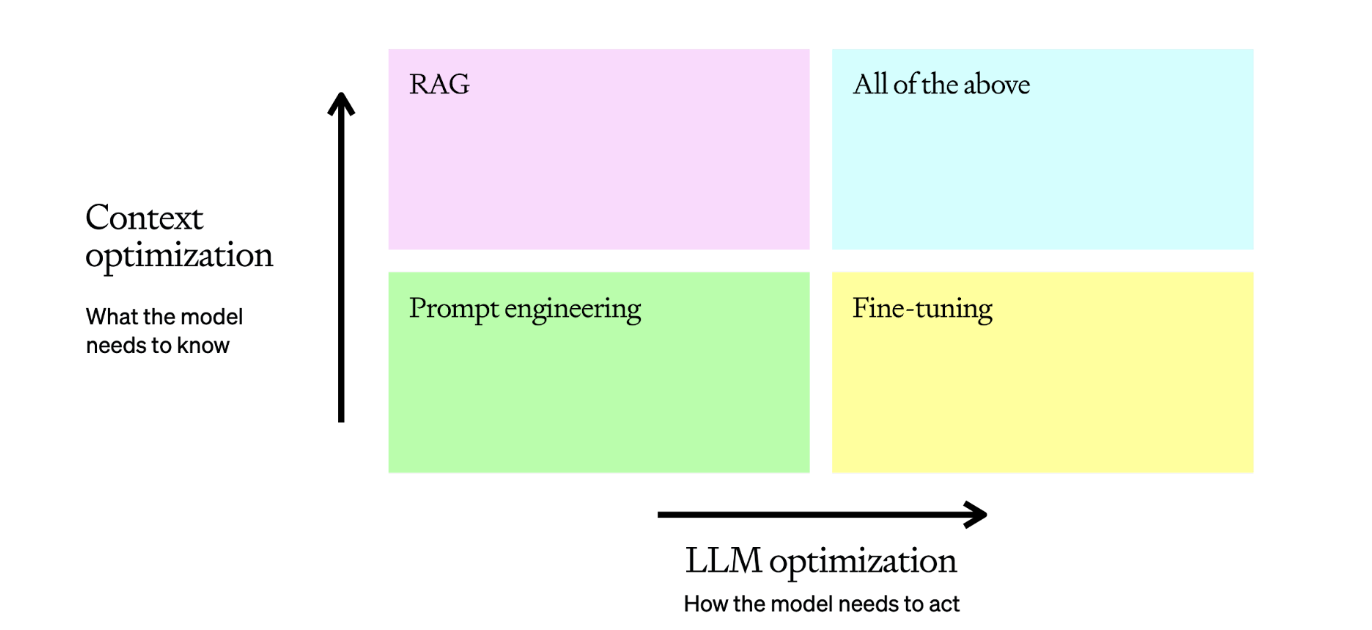
-
Context optimization (RAG): Adding relevant context when the model lacks knowledge, is out-of-date, or needs proprietary information. This maximizes response accuracy.
-
LLM optimization (Fine-tuning): Tuning the model itself when outputs are inconsistent, formatting is incorrect, tone/style is off, or reasoning is not followed. This maximizes consistency.
The optimization process involves iterating through these strategies, evaluating results, forming hypotheses, and re-assessing next steps.
A typical journey may look like:
- Prompt engineering to establish baseline
- Adding few-shot examples to improve consistency
- Introducing RAG for dynamic relevant context
- Fine-tuning on 50+ examples for higher consistency
- Tuning retrieval and fact-checking to reduce hallucinations
- Re-training fine-tuned model on enhanced examples
When Fine-Tuning Shines
Fine-tuning tends to be most valuable when you have data or requirements that differ significantly from the pre-training data of the foundation models. A few examples:
-
Specialized domains: If you're working with niche data that is highly domain-specific and unlikely to be well-represented in the LLM's training data (e.g. human data annotated in a custom format, proprietary corporate data, niche technical fields), fine-tuning can help to adapt the LLM to your unique data and terminology.
-
Non-English languages: Most LLM companies are not prioritizing non-English LLMs. If you're working with non-English data, especially in a specialized domain, fine-tuning can dramatically improve performance over an off-the-shelf model.
-
Output consistency: Fine-tuning enables you to train the model to adhere to specific output formatting. This is useful for function calling, specific JSON ouput, or consistent voice.
-
Cost and latency reduction: For high-volume use cases, fine-tuning a smaller model can dramatically reduce costs and latency compared to using a large general-purpose model for each request. This can save a lot of tokens if you have a large system prompt with instructions for explaining the desired output.
-
Traditional NLP tasks: For tasks like part-of-speech tagging and feature extraction, fine-tuning can close the gap between LLMs and traditional NLP pipelines trained on task-specific annotated data. For many classification tasks, dedicated NLP pipelines still offer advantages in terms of accuracy, efficiency, consistency, and cost-effectiveness.
See this comment from the author of SpaCy on using LLMs for NER:
So, here's something that might surprise you: ICL actually sucks at most predictive tasks currently. Let's take NER. Performance on NER on some datasets is below 2003.
Here's a simplified example of how fine-tuning can reduce the size of the system prompt for a customer call summarization use case.
Before fine-tuning (long system prompt with many rules and long instructions):
Please summarize the following customer service call transcript. The summary should:
<instructions here>
Business rules:
<rules about what to include, what to exclude, etc. here>
Negative example:
<examples here>
Positive example:
<examples here>
Transcript:
<transcript here>
Summary:
After fine-tuning:
Summarize the customer call:
<transcript here>
Summary:
Getting Started with Fine-Tuning
If you've decided that fine-tuning is the right approach for your use case, here are some tips for getting started:
- Use QLoRA, axolotl, and a good foundation model like Llama or Mistral
- Rent an A100 or H100 GPU with 80GB VRAM on vast.ai, RunPod, or a similar service. This can fine-tune 70B open models. You might be fine with 4090s for smaller models.
- If you don't have training data yet, you can generate them using GPT-4o and few-shot prompting (with good examples).
- Start by validating your hypothesis on a smaller model. If the results are promising, consider full-precision training for marginal gains.
- The LocalLLaMA subreddit has many useful tutorials and the community will help you with any questions
When to Stick with Prompt Engineering and RAG
In many cases though, prompt engineering and RAG can get the job done:
-
Internal corporate data: For proprietary data (without special formatting) that the LLM has never seen, adding the relevant context on-the-fly with RAG is usually the right choice.
-
Mainstream domains: If your use case falls into a domain that is likely to be very well-represented in the LLM's training data (e.g. general Q&A, summarization of news articles, code generation), prompt engineering alone can get you very far.
-
Up-to-date data: In fields where the underlying data is changes frequently and back-traceable outputs are needed, RAG is the right choice.
-
Rapid prototyping: Investing in fine-tuning is usually premature if you're still defining your product and iterating on the user experience. Prompt engineering is the faster way to experiment.
The Importance of Evals
Regardless of whether you choose to fine-tune or not, investing in high-quality eval data and a systematic eval process is important. An eval system allows you to systematically compare different prompts and models, and catch regressions early.
Having plenty of eval data makes it easier to experiment with fine-tuning and compare the results.
There are many good tools available to help with a standardized and efficient evaluation process, such as promptfoo.
Conclusion
In many cases, prompt engineering and RAG the most efficient and effective approaches. Fine-tuning remains a valuable tool in some scenarios though, especially when dealing with specialized data, strict output requirements, or cost constraints.
At Kadoa, we ended up focusing on having an eval system for our core use cases, an architecture that makes switching to new models easy, and selectively fine-tune for specific high-volume tasks where the performance gains justify the investment.

Related Articles

Introducing Kadoa Assistant, powered by our Web Scraping OS
Announcing a fundamentally better way to extract web data

How AI Is Changing Web Scraping in 2026
Explore how AI is changing web scraping in 2026. From automation and data quality to compliance to scalability and real-world use cases.

The Top AI Web Scrapers of 2026: An Honest Review
In 2026, the best AI scrapers don't just write scripts for you; they fix them when they break. Read on for an honest assessment of the best AI web scrapers in 2026, including what they can and cannot do.