How to Scrape Job Postings With AI
 Tavis Lochhead,Co-Founder of Kadoa
Tavis Lochhead,Co-Founder of KadoaMany businesses rely on job posting data, whether it's for building a job board, analyzing labor market data, tracking the hiring activity of competitors, or finding leads based on hiring information.
This usually means you have to set up bespoke web scrapers for each source, transform and clean the data, and integrate it into your database.
The main challenge is that job postings are very diverse and essentially just a chunk of text. Every company chooses a different structure for their job postings, uses a different design and layout, and might even protect it with anti-bot measures.
Let's explore how AI can fully automate job posting scraping at scale.
Job Posting Data Structure
Job postings usually consist of the same basic information, such as job title, description, salary, location, and a few more.
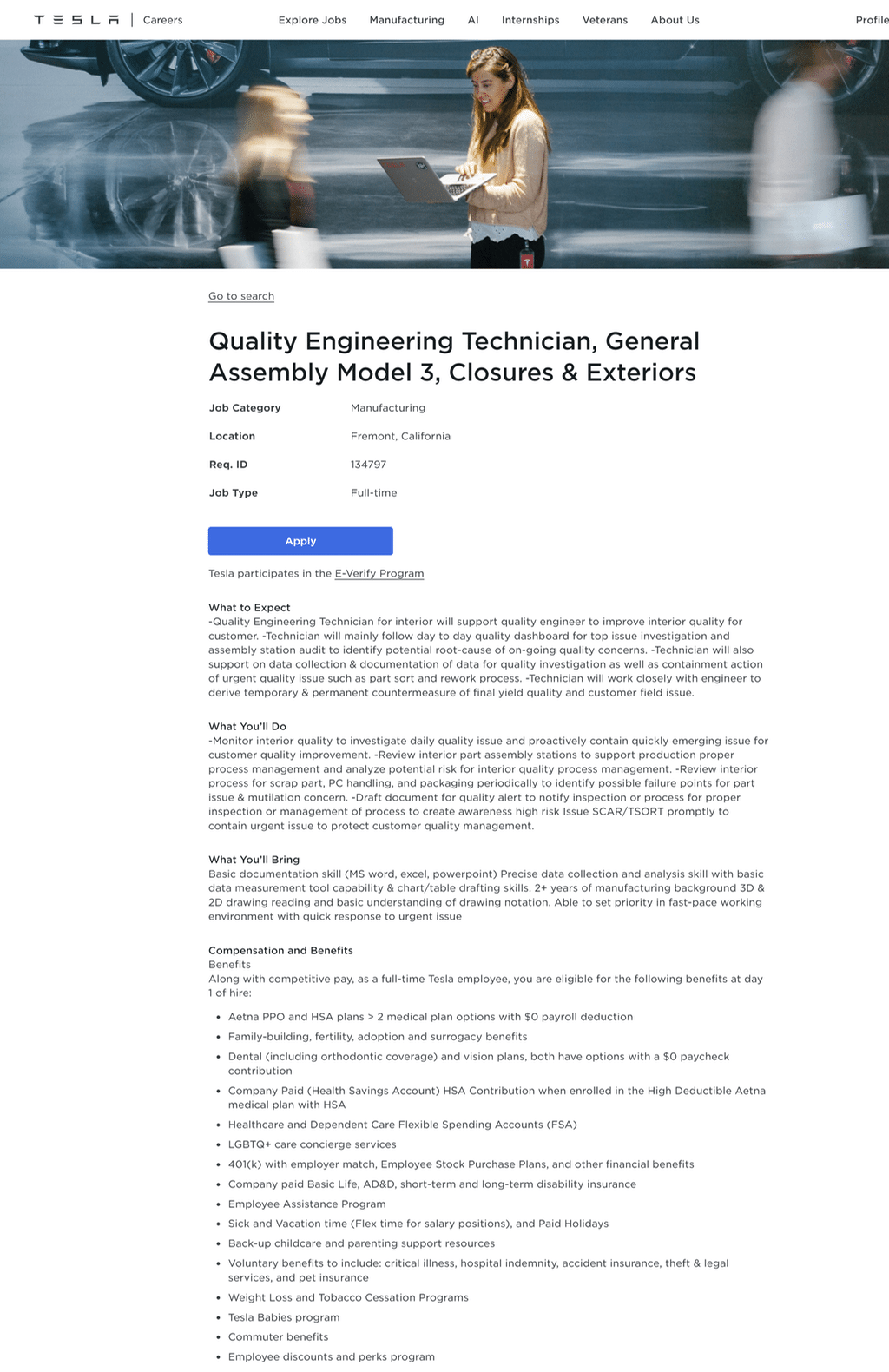
Crucial details such as salary and location frequently appear within table or list-style formats, while other key information is embedded in the job description.
You can already see the challenge: everybody does it differently and there is no agreed upon standard structure of a job posting. Almost non.
Google Job Posting Schema
In order to index all job posting properly, Google has introduced a structured data format that enables website owners to optimize their job listings for Google Search, making sure that all the key fields are easily accessible and indexed. Adhering to this schema increases the visibility of the posting and helps potential applicants to find job opportunities more efficiently.
{
"identifier": {
"@type": "PropertyValue",
"name": "Adobe",
"value": "R142966"
},
"hiringOrganization": {
"@type": "Organization",
"name": "Adobe",
"sameAs": "https://careers.adobe.com/us/en",
"url": "https://careers.adobe.com/us/en/job/R142966/Enterprise-Account-Director",
"logo": null
},
"jobLocation": [
{
"geo": {
"@type": "GeoCoordinates",
"latitude": "34.92369230000001",
"longitude": "-85.1910173"
},
"address": {
"@type": "PostalAddress",
"postalCode": "ADOBE",
"addressCountry": "United States of America",
"addressLocality": "Remote",
"addressRegion": "Georgia"
},
"@type": "Place"
}
],
"employmentType": ["FULL_TIME"]
}
The Google Job Posting schema, though helpful, often falls short due to incomplete or missing information as many companies don't follow the guidelines. These inconsistencies make it necessary to still scrape the entire job posting to accurately extract and structure all relevant data fields independently.
Understanding the Importance Of Structured Job Data
Before delving into the process, let's comprehend why structured data is crucial:
- SEO (Search Engine Optimization): Structured job data can enhance your website's SEO. Search engines favor well-organized content, making your site more prominent in job-related search results.
- Filling Gaps in Job Board Listings: Some job boards may not encompass all job opportunities in a specific niche. Data extraction can enrich your job board with additional listings, ensuring comprehensiveness for job seekers.
- HR Tech: For businesses offering HR solutions, consistent structured job data facilitates automation and hones algorithms for job matching and talent acquisition.
- Market Intelligence: Discern job market trends, skill demands, prevalent job types, and more to aid educational institutions and businesses in strategic decisions.
- Sales Intelligence: In the B2B sector, knowing which companies are hiring offers insights into business growth and potential expansion areas.
Step-by-Step Guide on Scraping Job Postings With AI
Step 1: Choosing the Right Job Posting Sources
You can either scrape career pages of companies or entire job boards. You should select sources that are most relevant to your industry, for example, platforms like 4dayweek.io are tailored for positions advocating a work-life balance through a four-day workweek.
Extracting job postings directly from company career pages has some advantages:
- Accuracy: By getting the job postings directly from the company's own career page, you're accessing the job posting at its origin. This approach avoids the pitfalls of aggregation seen on job boards, where some details can be lost or altered in the process.
- Real-Time Updates: Company career pages are continuously updated to reflect their current hiring needs. This means the job postings you extract are always up-to-date, providing a real advantage in rapidly changing job markets where timely information is crucial.
Step 2: Choosing the Web Scraping Tool
After selecting your desired job posting sources, the next step is configuring web scrapers for each source for extracting the data programmatically.
There are many traditional rule-based web scraping tools available, including Octoparse, Browse.ai, or Zyte, where you have to manually set up a bespoke web scraper for each source. Due to the diversity of career pages and job boards, this is a very tedious and time-consuming task.
A new generation of fully automated AI-powered web scrapers like Kadoa make it possible to instantly set up web scrapers, regardless of the source. The Kadoa agent automatically navigates, extracts, and transforms the desired job posting data, no matter the source.
Step 3: Setting up Your Scrapers
After selecting your tool and sources, you now need to set up your scrapers.
With an AI-based tool like Kadoa, the only information you need to add is the source URL and the desired update frequency, everything is taken care of automatically.
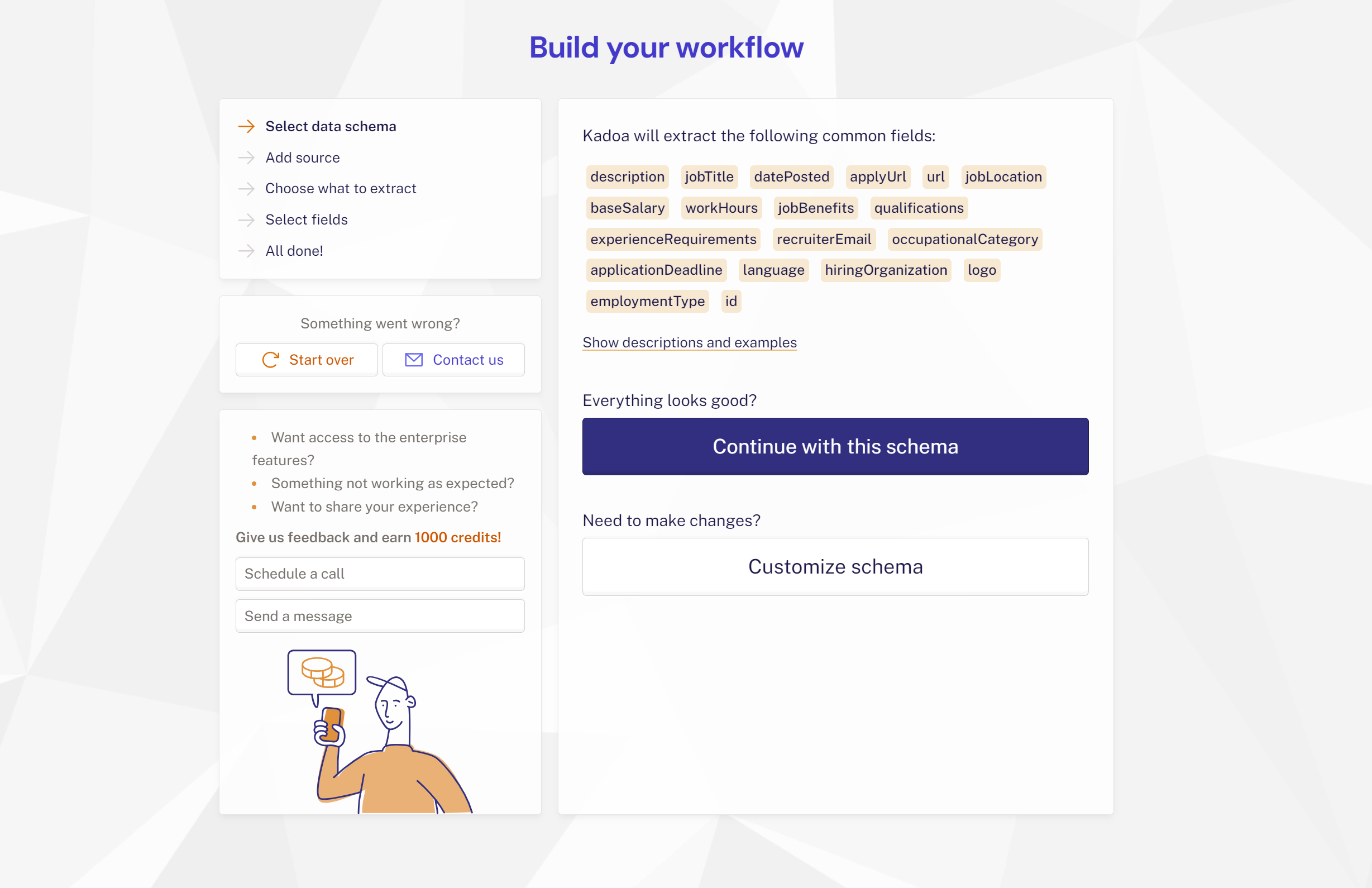
Step 4: Extracting and Structuring the Data
Following the setup of your scrapers, the next step is to trigger the scraping process where the web scrapers collect the unstructured data from the chosen sources.
After that, you usually have to clean and normalize the data into the same format. This is usually done by writing custom code or using a no-code backend solution.
Kadoa takes care of all the data transformation from the different sources, and you can just focus on your desired schema, which usually looks like this for job postings:
- Job Title: Indicates the position and seniority level.
- Job Description: Details job duties and required qualifications.
- Posting Date: Shows when the job was listed, highlighting urgency.
- Job Location: Specific place of work.
- Job Location Type: Identifies if the job is on-site, remote, or hybrid.
- Organization Details: Provides company size, industry, and reputation.
- Salary: Compensation range.
- Benefits: Health, retirement plans, perks.
- Experience Level: Specifies required experience range.
- Education Requirements: Lists necessary educational background.
- Employment Type: Defines the job as full-time, part-time, etc.
- Contact Information: Offers application or inquiry contact details.
- Apply URL: Direct link to apply for the job.
These are just the most common default fields, and you can customize the schema based on your needs.
Step 5: Integration and Data Analysis
With the data now extracted, cleaned, and structured, you can leverage the structured data for various applications such as expanding your own job board, talent acquisition strategies, industry trend analysis, and deriving valuable market insights.
Case Study
To illustrate the efficiency boost and cost savings of automated job scraping, let's explore a compelling case study from a leading European job board:
Before: Traditional Scraping
- The process consumed approximately 7 days
- It required manual data pipeline building and integration of different external tools.
- Constant maintenance and testing were required.
- Custom code was necessary for each data source, leading to a slow turnaround with developers and error-prone data.
After: Automating Job Scraping With AI
- The timeline shrank to just a few minutes.
- Kadoa automated the manual work equivalent of 2 full-time employees (FTE).
- It established fully automated data workflows for 500 web sources.
- The solution offered was not only faster and cheaper but also ensured better scalability and maintenance-free operation.
- The outcome was more consistent data, devoid of the human error previously plaguing the process.
Conclusion
Scraping job postings used to be a tedious and time-intensive task as you had to hire developers who used web scraping tools and custom code to extract and structure the job postings from each source.
The rise of AI made it possible to put such work on full autopilot, where an AI agent automatically finds, extracts, and transforms the job posting data, no matter the source. If a website changes, the AI automatically adapts to it, making the scraper completely maintenance-free.
This leads to massive cost savings compared to the traditional scraping approaches.

Related Articles

How to Build a Job Board in a Day
Learn how to effortlessly make a job board using job board software and the Kadoa jobs scraper.

What is Web Scraping? Enterprise Use Cases for 2026
A comprehensive enterprise guide to web scraping in 2026. How to run it at scale, where AI helps, how to stop losing engineering hours to maintenance, and what separates platforms worth evaluating.

The Best Web Scraping Tools in 2025: A Comprehensive Guide
Discover the best web scraping tools of 2024. We compare traditional players and new AI-powered solutions to help you make an informed choice.