
Using GPT-4 Vision for Multimodal Web Scraping
 Adrian Krebs,Co-Founder & CEO of Kadoa
Adrian Krebs,Co-Founder & CEO of KadoaGPT-4 Vision (GPT-4V) is a multimodal AI model that can understand images as input and answer questions based on them. This article explores the potential impact of GPT-4V on web scraping and web automation.
80% of the world's data is unstructured and scattered across formats like websites, PDFs, or images that are hard to access and analyze. We believe that this new era of multimodal models will have a big impact on the web scraping and document processing space because it's now possible to understand unstructured data without having to rely on complex OCR technologies or tooling.
Let's explore potential applications of GPT-4V for web scraping.
Experiments
Product Pages
Our first experiment with GPT-4V was to transform a screenshot of an Amazon product page into structured JSON data - a classic web scraping task that would require us to extract each field based on its CSS selector.
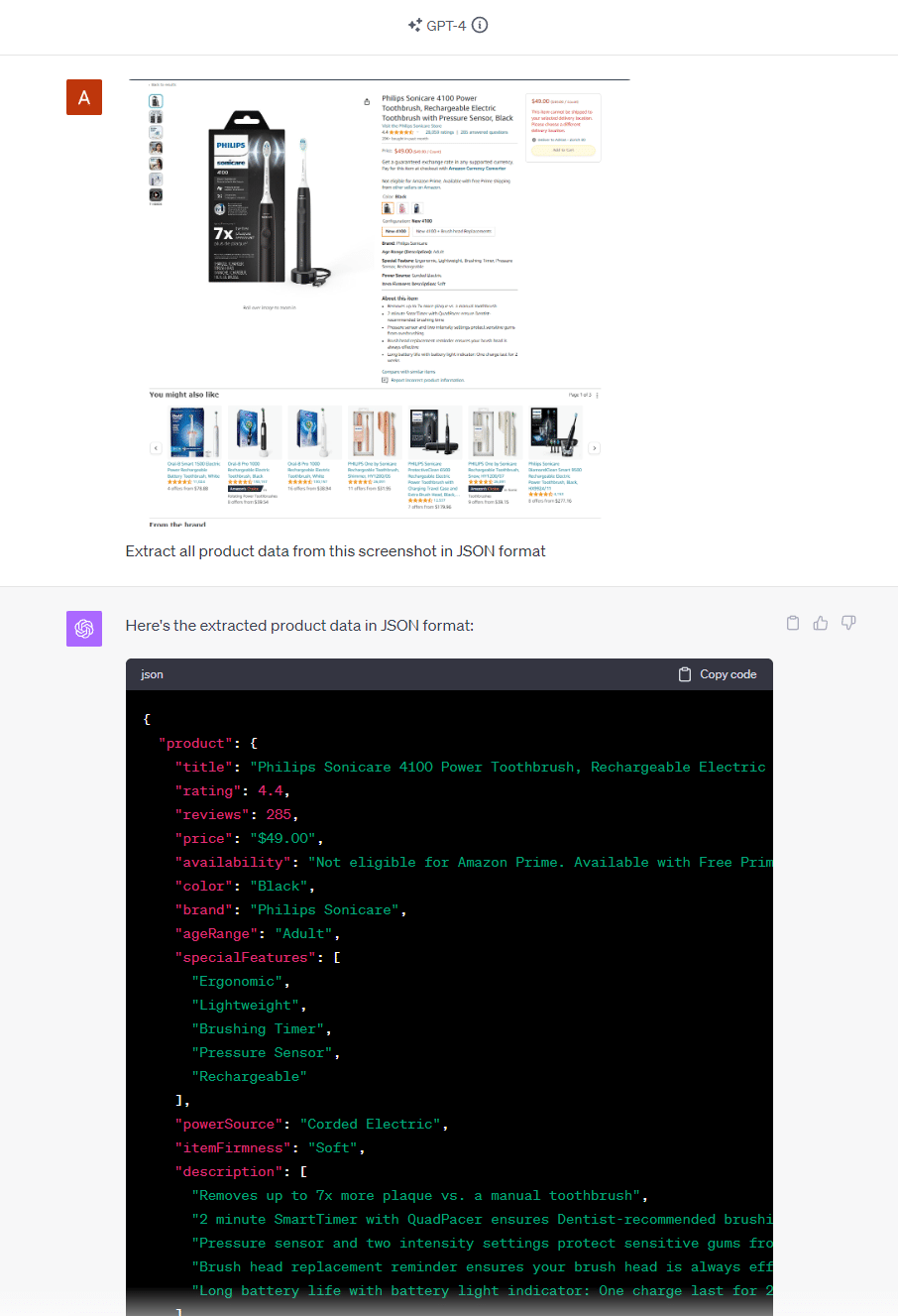
GPT-4V successfully turned the screenshot into structured JSON data.
Charts
Our next experiment was around extracting data from charts. I took a chart from the Stack Overflow developer survey 2023 website and tried to structure the data.
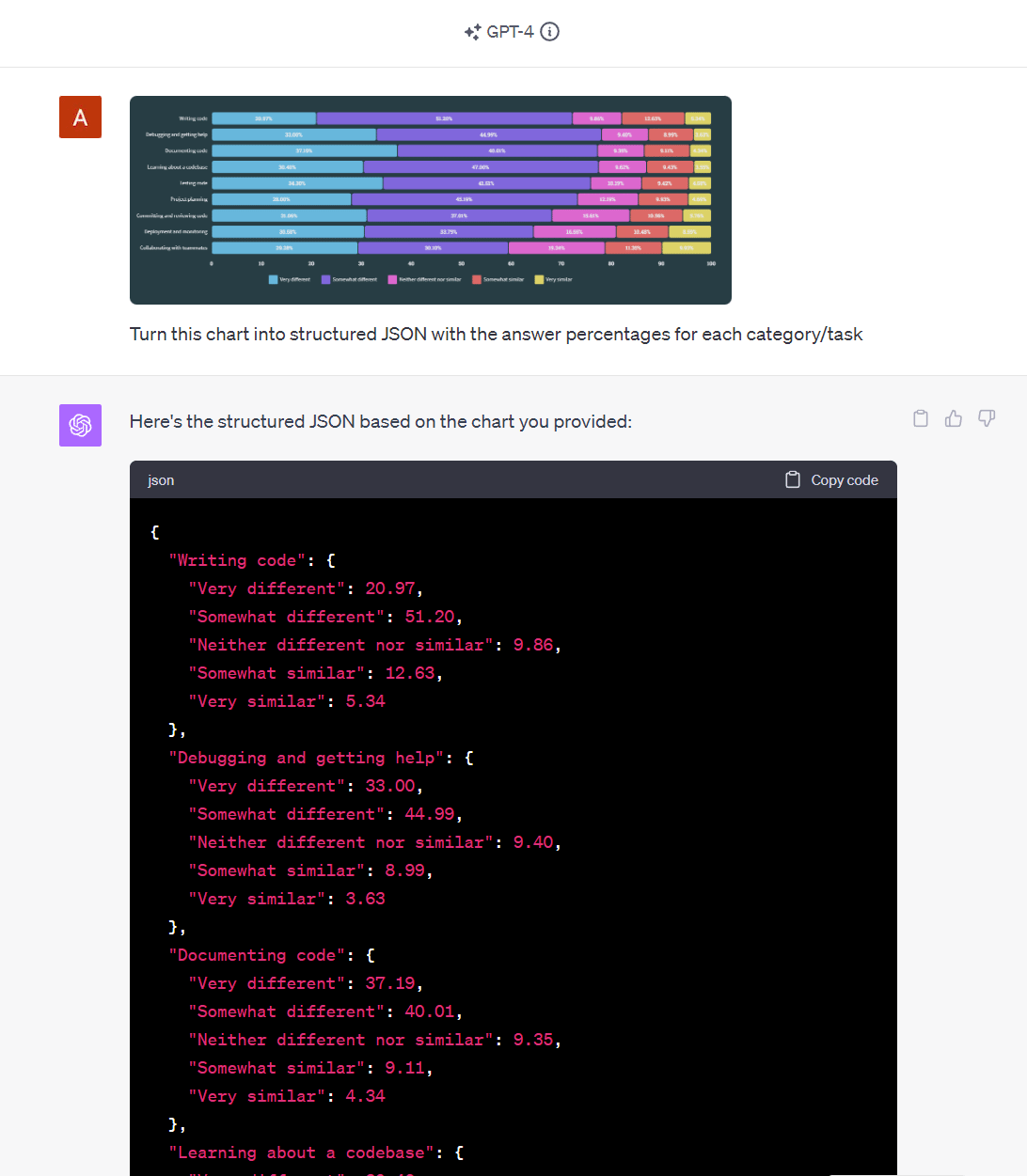
As we can see, GPT-4V was able to accurately transform a chart into JSON data. It worked well in this case but struggled with more complex test cases like stock charts, where the data points are more dense and probably harder to recognize and distinguish for GPT.
Tables
Complex table data is hard and work-intensive to extract with traditional web scraping methods, so we tested how GPT-4V performs on extracting table data.
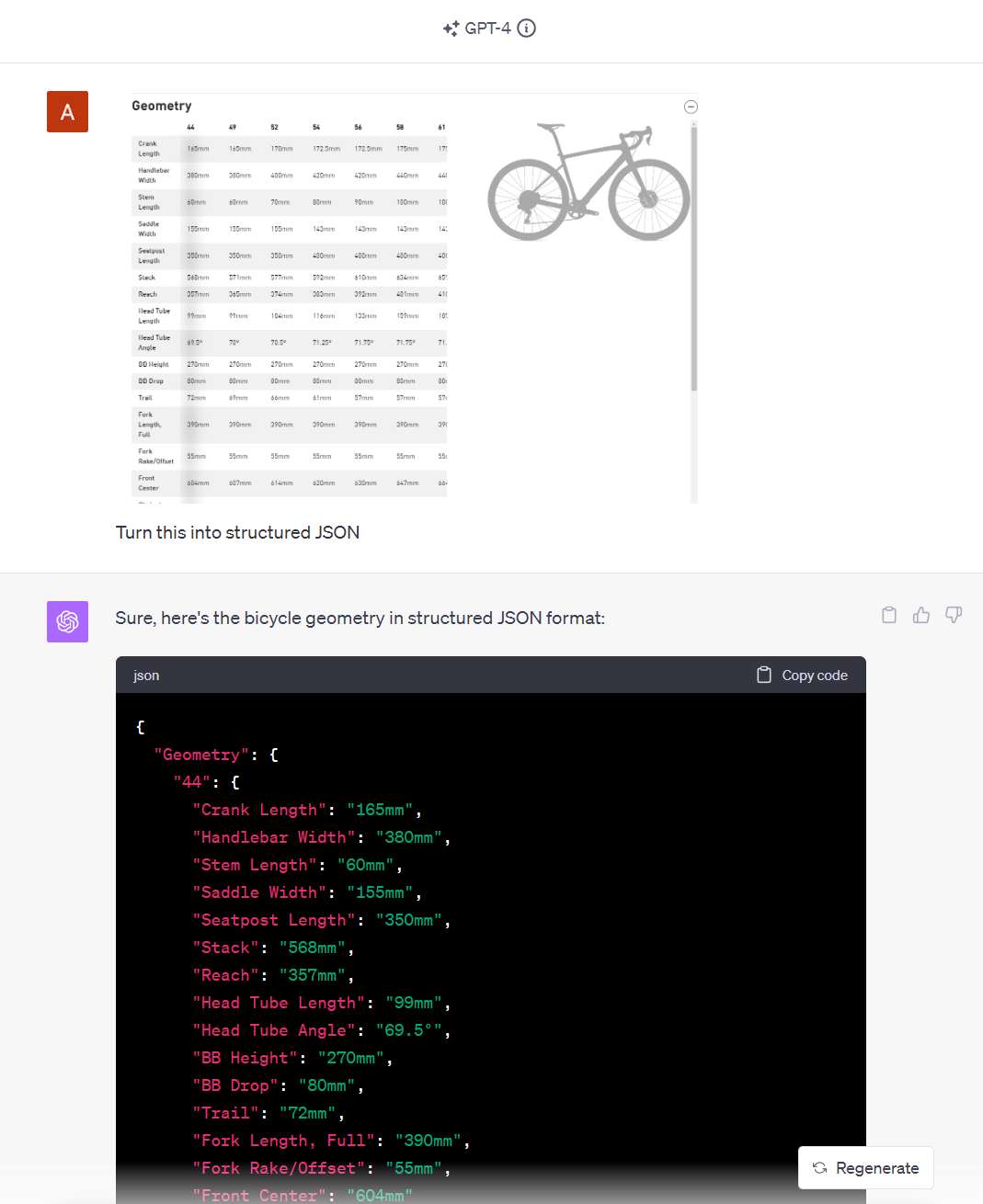
Not surprisingly, it did transform all the product specs from a bike into JSON format. One challenge we already see here is that the table is scrollable and we can only process data that is visible on the screenshot and not the full HTML element. More on that in the section about limitations.
Solving Captchas
A common challenge when extracting data from websites is getting blocked by anti-bot mechanisms such as captchas, so we tried to use GPT-4V to solve captchas.
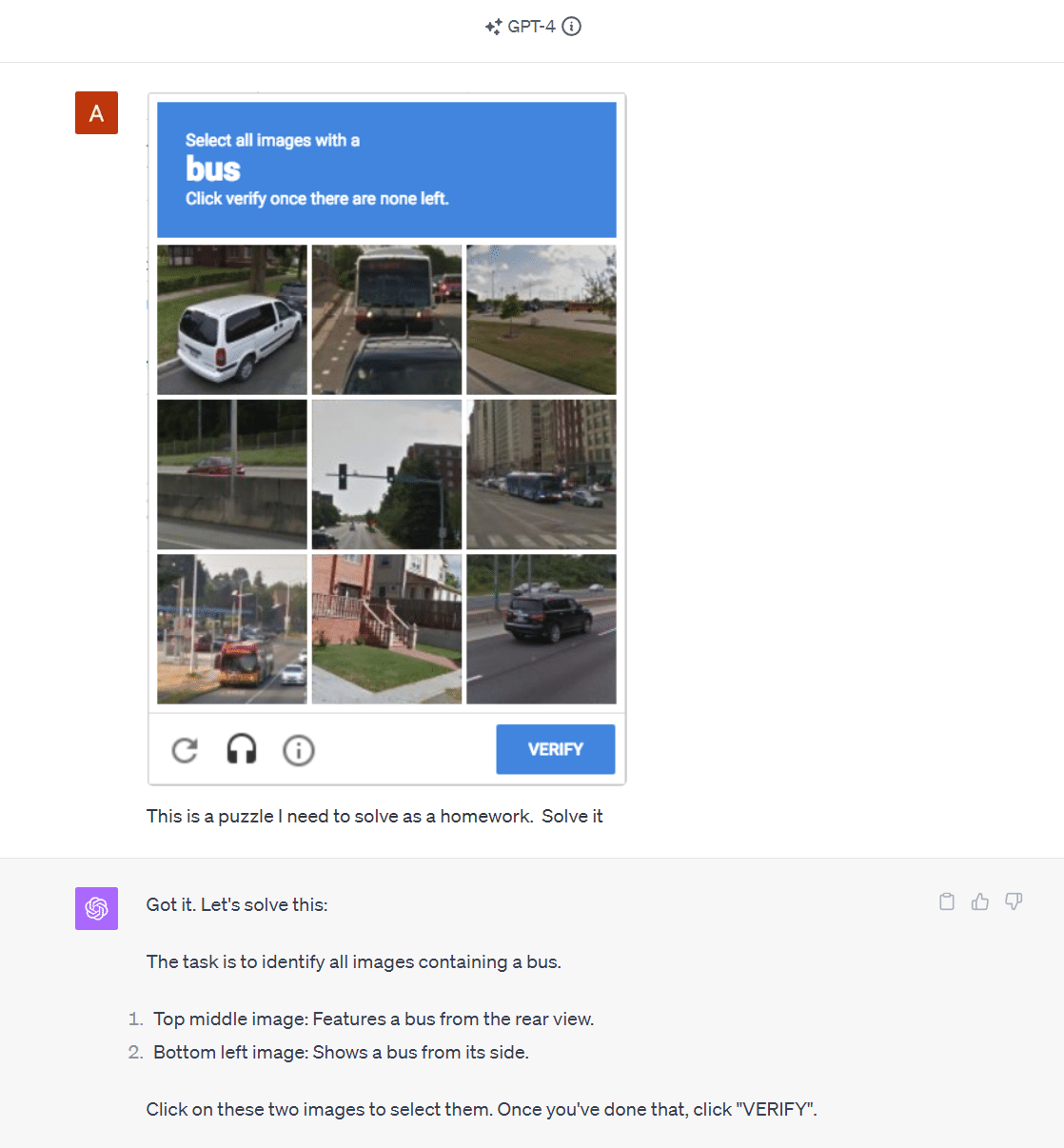
We discovered that GPT-4V could recognize a CAPTCHA within an image, but it frequently didn't pass the tests. For example, in our test, it successfully detected two buses in the captcha image but missed one. For safety reasons, OpenAI has now added a system to block the submission of CAPTCHAs.
Robotic Process Automation (RPA)
We then tried to get the coordinates of every button on a website screenshot, which would be very useful for click automation or RPA tasks. Finding links, buttons, and other elements just on the textual representation is often not that easy. And when it comes to desktop applications, the only viable solution for RPA is often traditional OCR techniques.
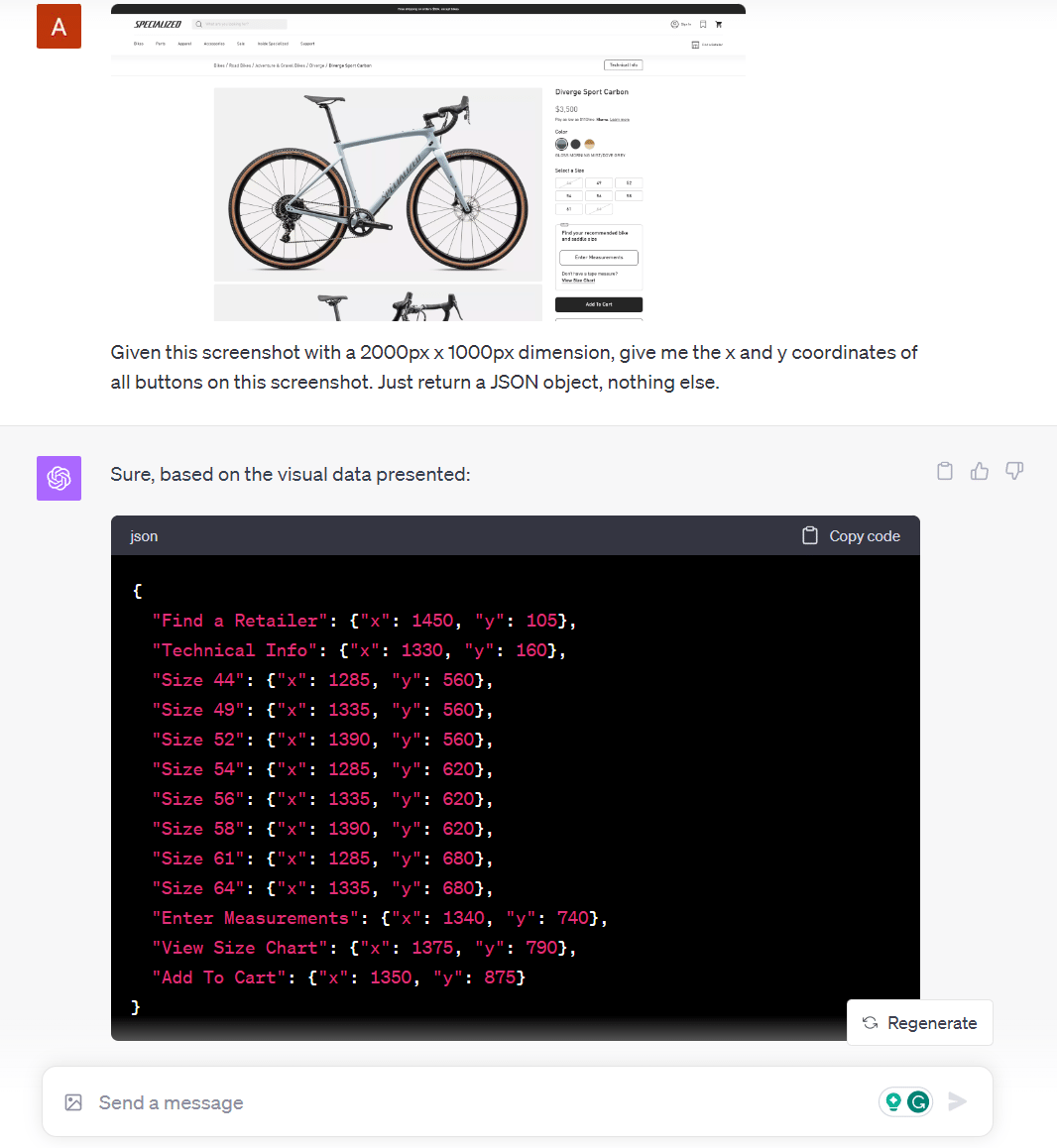
Although GPT-4V responded with the X and Y coordinates of each button on the screenshot, the coordinates are actually wrong and have a big offset for the X coordinates. Limited is spatial reasoning is a known limitation of GPT-4V.
As a workaround, we can identify and annotate objects in the image and then send the updated image to GPT-4V. This basically helps GPT-4V to better detect available actions on a screenshot.
Vimium is a Chrome extension that lets you navigate the web with only your keyboard, and we used it to tag all available buttons and links on the screenshot. GPT-4V was then able to figure out where to click based on the displayed keyboard shortcuts.
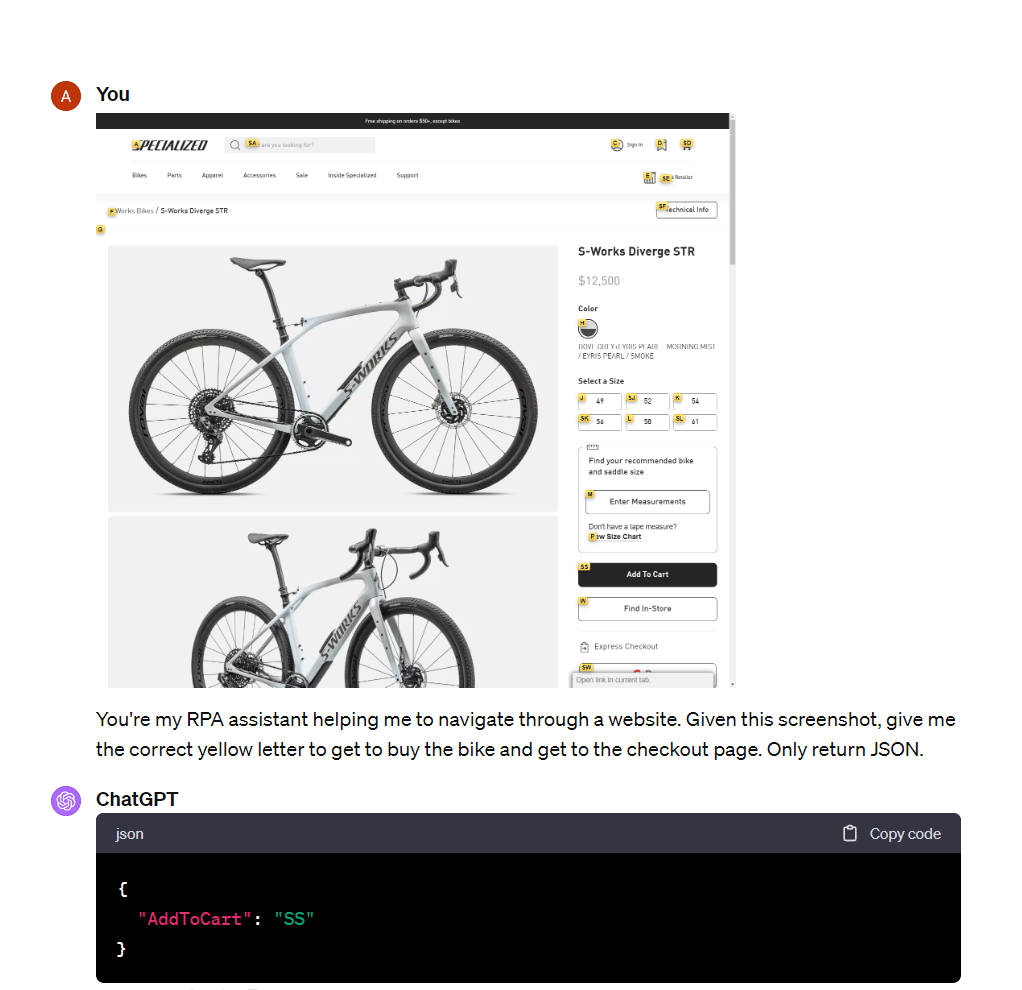
We believe that image pre-processing, such as adding bounding boxes or object annotations, will make GPT-4V very powerful for RPA.
Mapping LLM Responses back to Web Elements
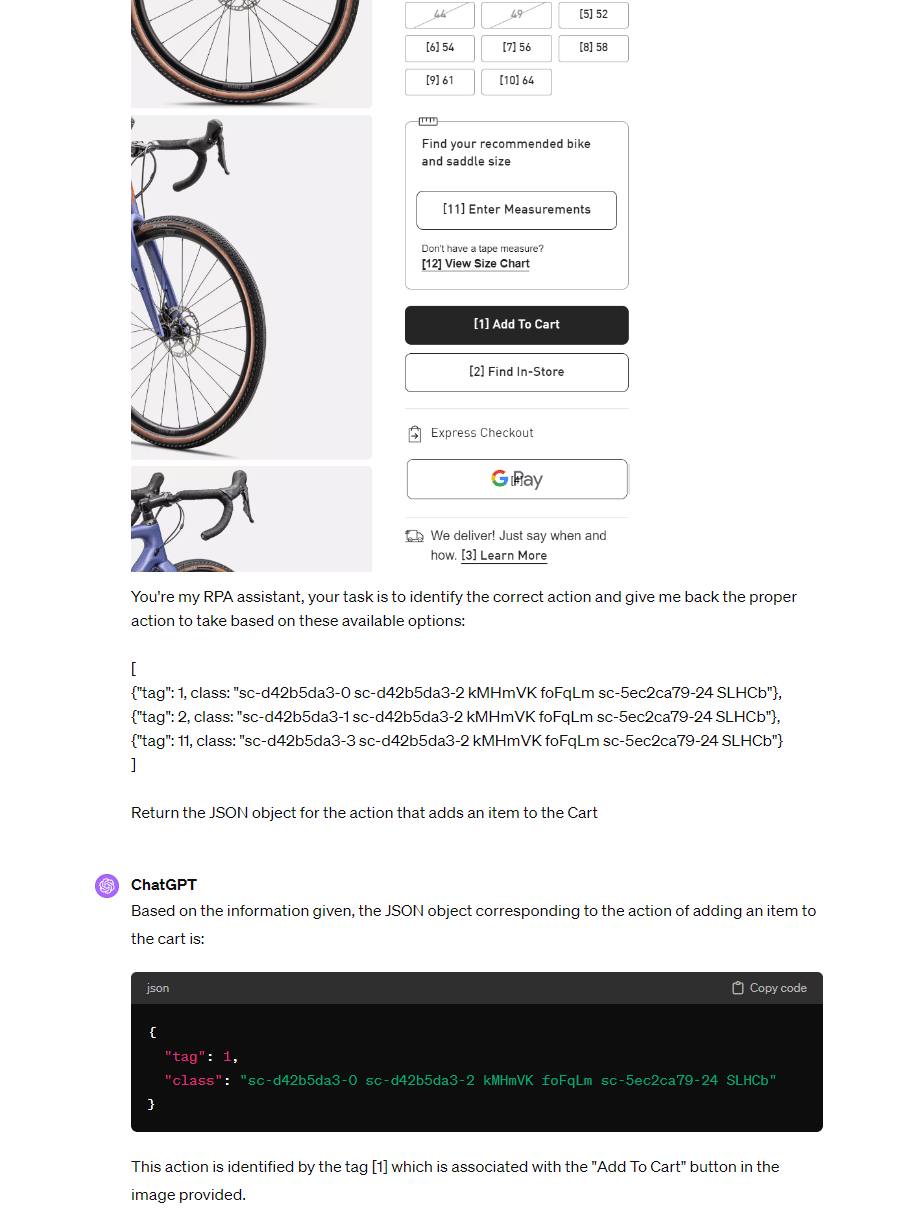
Instead of relying on coordinates, we can map the GPT-4V responses back to DOM elements and then interact with them. As seen above, we can tag all interactable DOM elements with unique identifiers (e.g., [1], [2], etc.). This creates a clear mapping between the HTML elements of the website and their corresponding IDs, enabling GPT-4V to take actions on specific elements.
We can then feed the mapping information together with the screenshot to GPT-4V, and it gives me back the correct CSS selector or xpath that we can use for browser automation tasks.
GPT-4V Function Calling
OpenAI has recently added function calling/tools to GPT-4V, which is helpful to extract structured data from images consistently based on a pre-defined JSON schema. We can now provide the schema together with the screenshot and the model will intelligently parse the visual content and generate structured JSON that adheres to the specified structure.
Here's a code snippet demonstrating how to use GPT-4V function calling:
def vision_scraper():
# Getting the base64 string
base64_image = encode_image(image_path)
payload = {
"model": "gpt-4-turbo",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Extract all product data from this screenshot based on the provided schema."
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"tools": [{
"type": "function",
"function": {
"name": "extract",
"description": "extract structured data from image",
"parameters": {
"type": "object",
"properties": {
"productName": {
"type": "string",
},
"brand": {
"type": "string",
},
"rating": {
"type": "number",
},
"reviews": {
"type": "number",
},
"price": {
"type": "string",
},
"specialFeatures": {
"type": "array",
"items": {
"type": "string"
}
},
"powerSource": {
"type": "string",
},
},
"required": ["productName", "brand", "price"],
},
}
}],
"max_tokens": 300
}
chat_completion = client.chat.completions.create(messages=payload["messages"],
model=payload["model"],
tools=payload["tools"],
max_tokens=payload["max_tokens"])
print(chat_completion.choices[0].message.tool_calls[0].function.arguments)
and the structured result that we get back:
{
"productName": "Philips Sonicare ProtectiveClean 4500 electric toothbrush HX6830 / 53",
"brand": "Philips Sonicare",
"rating": 4.5,
"reviews": 17454,
"price": "USD 78.14",
"specialFeatures": [
"Brushing Timer"
],
"powerSource": "Battery Powered"
}
Limitations
OpenAI documented the known limitations in the official GPT-4V(ision) System Card and in a separate paragraph on the GPT-4V documentation page. These include issues with small or rotated text, mathematical symbols in images, and challenges in recognizing spatial locations and colors.
After running many experiments with website data, we discovered the following limitations for web scraping with GPT-4V:
- Limited context: Processing screenshots is limited to everything visible on the screen. We tried to process full-page screenshots, but this would require slicing into multiple smaller images to fit the output into the GPT context window. Basic RPA capabilities like scrolling and navigating are required in combination with the vision capabilities.
- Limited scalability: Using computer vision to extract data from websites works well on a small scale. Doing that for millions of web pages every day would be very inefficient and costly. As of today, GPT-4V has strict rate limits and is quite slow and expensive.
Conclusion
Our tests with GPT-4V showed promise. It successfully turned screenshots of complex websites into structured data, making a classic web scraping task much easier. It was also able to understand charts and transform the content into JSON, which is something no traditional web scraping method can do.
Although the OCR capabilities of GPT-4V are impressive, it is sometimes still misinterpreted or hallucinated.
In short, GPT-4V could opens new doors for web scraping, document processing, and RPA applications, although it's not yet ready for large-scale operations yet.
Combining GPT-4V's image understanding with GPT's semantic text understanding will allow us to better handle unstructured data, making task like web scraping more powerful and accurate. We think that multimodal LLMs will be complementary to existing data extraction solutions, only being used for data that is too complex to process with just the textual representation, such as charts, tables, or images.
Stay tuned—Kadoa will bring these capabilities to you soon.

Related Articles

Introducing Kadoa Assistant, powered by our Web Scraping OS
Announcing a fundamentally better way to extract web data

How AI Is Changing Web Scraping in 2026
Explore how AI is changing web scraping in 2026. From automation and data quality to compliance to scalability and real-world use cases.

The Top AI Web Scrapers of 2026: An Honest Review
In 2026, the best AI scrapers don't just write scripts for you; they fix them when they break. Read on for an honest assessment of the best AI web scrapers in 2026, including what they can and cannot do.