
The AI Flywheel Effect
 Adrian Krebs,Co-Founder & CEO of Kadoa
Adrian Krebs,Co-Founder & CEO of KadoaThe big winners of the recent launches of open models like Llama 3.1 and Mistral Large Enough are developers and AI startups. They no longer face vendor lock-in and can now deeply integrate AI into their products in a very cost-effective and performant way.
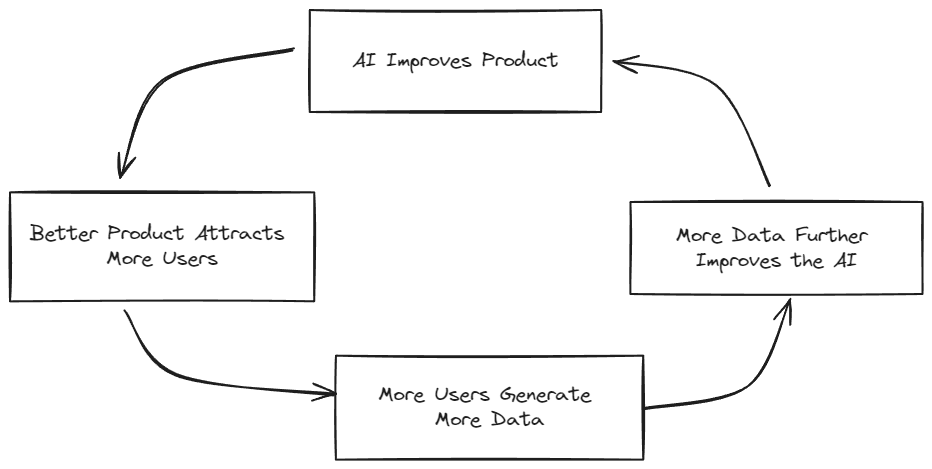
The key for every AI startup is to identify a problem where your product benefits from AI advances, which then creates a powerful flywheel effect:
- Better AI models improve your product
- Enhanced product attracts more users
- More users generate more data
- More data further improves the AI
It's as if your product automatically becomes better, cheaper, and more scalable with every major AI advancement.
A few startups, such as Perplexity and Character.ai, have nailed this. They started with slow and expensive models like GPT-3 but have since benefited from major advancements in speed, quality, and cost.
Here is how this journey went for us:
Increasing token limits
One of the first hurdles we encountered with early LLMs was the limitation of limited context windows.
Before processing larger data, we had to slice the input data into multiple smaller chunks while still keeping the overall context.
This was both error-prone and slow.
As context windows increased rapidly, we reduced the number of LLM calls and increased reliability. Another limiting factor were the rate limits at the beginning, which have been largely resolved as well. Here's how context window capacities have evolved over time:
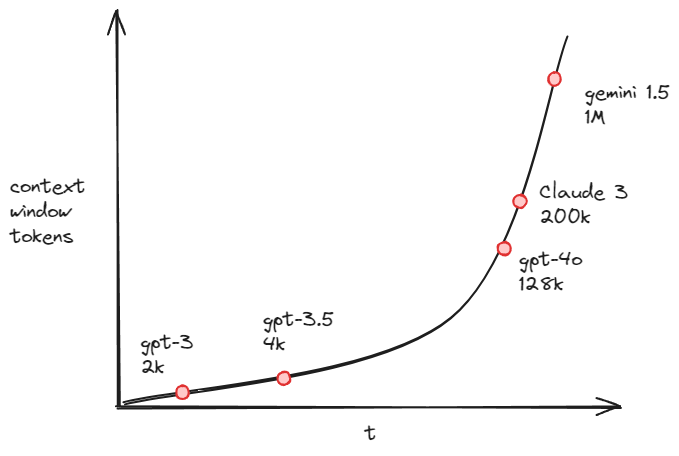
The models keep increasing the input limit to very large amounts, but output has been stuck at 4k - 8k tokens. GTP-4o mini now has a 16k output token limit, which indicates we'll see similar increases for future model releases. This is especially useful for processing large documents (e.g. PDFs or in our case, websites) without having to break it up into chunks and stitching the outputs together again.
Price race to the bottom
When we started out with GPT-3, it was very expensive, making it hard to scale and achieve viable unit economics. Over the last 2 years, we've seen a ~98% cost drop, which massively decreased our costs and improved our margins.
Thanks to Way Back Machine I was able to find the original GPT-3 Davinci pricing, otherwise it's very hard to track the price changes'.
Here's a simplified chart showing how 3rd party LLM prices have changed over time:
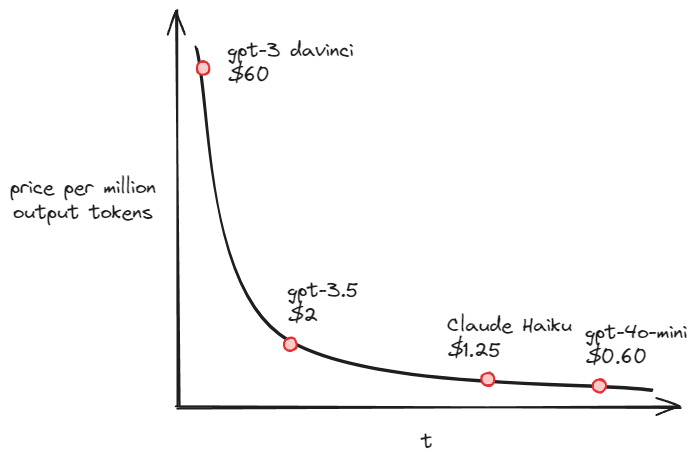 This chart does not yet include the inference pricing for Llama 3.1 or Mistral Large Enough, which will be even cheaper.
This chart does not yet include the inference pricing for Llama 3.1 or Mistral Large Enough, which will be even cheaper.
This price race to the bottom opens up many new opportunities for startups as very cost-effective and near-instant LLM responses have become a reality.
Hosting and fine-tuning LLMs has become easy
Rapid advances in OS models, tooling, and frameworks have reduced the operational overhead to host or fine-tune our in-house models.
This has further improved scalability and efficiency for large-volume LLM tasks with structured output.
A typical fine-tuning setup today could look like this:
- Use QLoRA, axolotl, and a good foundation model like Llama or Mistral
- Rent an A100 or H100 GPU with 80GB VRAM on vast.ai, RunPod, or a similar service. This can fine-tune 70B open models. You might be fine with 4090s for smaller models.
- If you don't have training data yet, you can generate them using GPT-4o and few-shot prompting (with good examples).
- Start by validating your hypothesis on a smaller model. If the results are promising, consider full-precision training for marginal gains.
- The LocalLLaMA subreddit has many useful tutorials and the community will help you with any questions
Differentiate with everything "non-AI"
Every startup still needs to build up defensibility and focus on differentiating with everything "non-AI" as the entry barriers become lower and established players integrate AI into their offerings while leveraging their distribution advantage.
Here are some strategies to consider:
- The best products will be defined by everything they do that's not AI, such as workflows, UIs, UX, and performance.
- Consider cost and performance limitations: LLMs can be inaccurate, expensive and slow. Sometimes there are traditional approaches that are more efficient.
- Avoid over-reliance on specific models: Find the right abstraction and have good evals to switch and deploy models quickly.
Conclusion
The AI flywheel effect is powerful for startups with AI-first products. Every major improvement in model quality, context windows, or cost drives adoption, leading to more users and data.
This data can then be used to further fine-tune and improve the AI, creating the flywheel.
Even though the current market favors incumbents that embed AI into their existing products and leverage their distribution advantage, there are still many opportunities for startups in creating differentiated solutions.
We're only at the beginning of AI adoption, similar to the early days of cloud adoption.
It's one of the most exciting times to build an AI startup.

Related Articles

Introducing Kadoa Assistant, powered by our Web Scraping OS
Announcing a fundamentally better way to extract web data

How AI Is Changing Web Scraping in 2026
Explore how AI is changing web scraping in 2026. From automation and data quality to compliance to scalability and real-world use cases.

The Top AI Web Scrapers of 2026: An Honest Review
In 2026, the best AI scrapers don't just write scripts for you; they fix them when they break. Read on for an honest assessment of the best AI web scrapers in 2026, including what they can and cannot do.