
Direct Data Sourcing at Scale
 Adrian Krebs,Co-Founder & CEO of Kadoa
Adrian Krebs,Co-Founder & CEO of KadoaFor years, getting structured datasets from public sources meant one of two things: buy off-the-shelf datasets from a data provider or hire a team to build and maintain your own scrapers. The first option is expensive and gives you the same data as everyone else. The second requires engineering resources that most firms don't have.
That's changing now as we're at a point where AI and cloud compute have reached a point where direct sourcing of public data at scale is possible for teams of almost any size. What used to require a team of engineers can now be done by a small team with the right tooling.
We're seeing this play out with our own customers, and the implications for the data provider market are significant.
LLM + compute as enablers
Two things came together.
First, LLMs got good enough at code generation and data extraction that you can point them at messy, unstructured sources and get clean, structured output.
Second, cloud compute and storage got cheap enough to run hundreds of data pipelines in parallel without crazy costs or a dedicated infrastructure team.
The combination means that sourcing data from public filings, websites, and databases is no longer a large-scale engineering project but rather something also small teams can now do.
Why firms start doing this now
We regularly talk to data teams at hedge funds, asset managers, and PE firms. The appetite for in-house sourcing at scale has increased over the past year thanks to the above technological enablers. Here are the main reasons why the idea of direct sourcing of public data is very appealing to them:
Coverage and depth
Vendors cover what's commercially viable. If you need data from mining companies in five different countries, or building permit filings across US municipalities, or central bank policy actions across emerging markets, you're often out of luck. The niche, bespoke datasets that create real edge are exactly the ones no vendor offers.
With direct sourcing, you define your own coverage and get the data in the proprietary format your models expect instead of having to deal with a generic schema designed for the broadest possible customer base.
Time to insight
Traditionally, an analyst or PM has a thesis, requests data from the central data team, waits two weeks, goes through compliance approval, and eventually gets a dataset that may or may not match what they needed.
With self-serve tooling, the investment teams can source the data directly. You can now just describe the dataset you need and get structured output. The feedback loop from thesis to data goes from weeks to hours, and the entire research process speeds up.
Cost efficiency
Many data providers charge significant fees for datasets that are ultimately sourced from public information. If the raw data is publicly available and the tooling exists to extract it reliably, the economics of paying a vendor start to break down.
Sometimes you only need a fraction of a vendor's dataset, but you still have to buy the whole thing. With direct sourcing, you get exactly what you need and nothing you don't.
Cost is not the primary driver for most firms, but utility and accuracy are. However, once you're sourcing data faster and with better coverage, the cost savings become hard to ignore.
Real-world examples
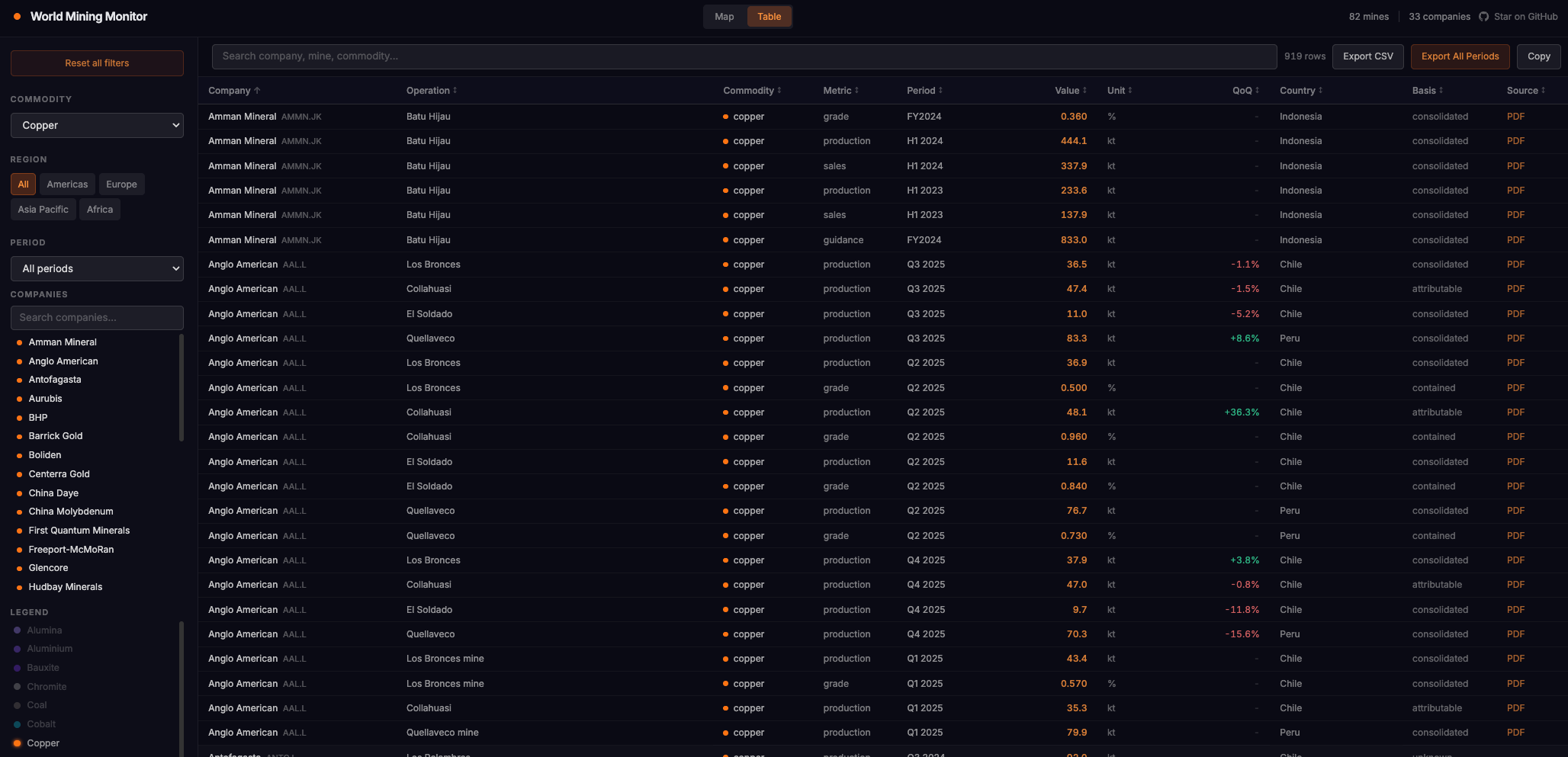
Once common example of a public dataset that can be soruced directly is specific KPIs of companies. As an example, we can now build a dataset of global mining production KPIs extracted from public filings (mining.kadoa.com, GitHub). The hard part is normalization since every region and company reports differently, and even for SEC filings, the KPIs are usually burried in the unstructured management discussion sections.
Traditionally it was very hard to get global coverage on data like this, and most large data providers still do it with a lot of human labor, but we can now automate data sourcing tasks like these at scale.
The main challenges are:
- Different units across reports like copper in kt, million pounds, or wet metric tonnes
- Fiscal years don't align
- Product naming is inconsistent (e.g. "copper concentrate" vs "cu conc")
- Some report on a payable basis, others contained metal, others equity-adjusted
We use LLMs to deterministically generate extraction, transformation, and validation ETL code for each company. If a source changes or data issues appear, the system can automatically adjust the code.
The pattern applies to any public data that's valuable but hard to collect at scale:
- Pharma and biotech: FAERS adverse events, clinical trial results, patent filings, contract awards
- Consumer and retail: SKU-level pricing, promotions, inventory signals, B2B spend data from app stores and marketplaces
- Real estate and construction: building permits, store location footprints, REIT tenant directories
- Corporate and IR: investor relations events, press releases, earnings data across thousands of companies
- Commodities: production KPIs, ISO energy pricing, agricultural market reports
- Central banks: monetary policy actions and rate decisions from emerging markets without machine-readable feeds
- Semiconductors and supply chain: equipment lead times, data center permit filings, OEM product availability
- Enterprise AI adoption: model provider announcements, AI marketplace listings, hiring patterns
The raw data is public in all of these cases. It's just scattered across thousands of sites in inconsistent formats.
Where this is going
If the sourcing and aggregation of public data can be done efficiently with AI, the value of a data provider has to come from proprietary methodology, unique access, processed signals, or coverage that goes beyond what's publicly available.
Simply curating public data and selling it at a premium is increasingly hard to defend. Firms are starting to ask: "If this data comes from public filings, why am I paying six figures for it?"
Direct data sourcing won't replace data providers. Datasets built on proprietary relationships, unique data collection methods, or complex cross-source linkage still have defensible value.
But small teams will use and build datasets that only large funds could produce and afford before. The investment industry's relationship with data will look more like what happened to media: the tools to produce got cheap, and the advantage moved from access to alpha generation.
We're building Kadoa to make this possible. If you want to explore what direct sourcing looks like for your firm, reach out.

Related Articles

Introducing Kadoa Assistant, powered by our Web Scraping OS
Announcing a fundamentally better way to extract web data

The AI Data Stack for Investment Research
How investment firms transform their data stacks to make best use of AI.

Alternative Data for Hedge Funds: A Practical Guide
What hedge funds actually need to build at scale: the signals worth tracking, the pipeline that holds up, and the compliance layer that doesn't block every new source.