
Introducing Kadoa Assistant, powered by our Web Scraping OS
 Adrian Krebs,Co-Founder & CEO of Kadoa
Adrian Krebs,Co-Founder & CEO of KadoaCollecting data from the web hasn't changed in decades and remains fundamentally broken, yet almost every business depends on it. Engineers write brittle scripts for each individual source and need to do constant maintenance. Every new scraper adds tech debt, and it's becoming prohibitive to scale. Ultimately the data ends up late, missing, or wrong.
Today, we are launching our Kadoa Assistant and Web Scraping OS to give everyone the tools to source web datasets at scale, with a speed and quality that wasn't possible before.
- Kadoa Assistant lets you build a web dataset with just a prompt. Non-technical users get data without writing code, and engineers build pipelines faster.
- Web Scraping OS is our AI data infrastructure that generates, maintains, and monitors data pipelines automatically. You get access to the infrastructure we spent years fine-tuning.
Kadoa Assistant
Imagine having a team of senior web scraping engineers always available to you and your team. We spent years building reliable, accurate scrapers by hand, reverse-engineered the tools and judgment that work takes, and encoded all of it in an agent. Now you have access to all of this through a simple chat interface.
Until now, setting up a web scraper meant either writing code or clicking through complex configuration wizards, inspecting pages, and manually fixing things whenever something broke. We don't think of the Kadoa Assistant as just a better tool, but a fundamentally better way to extract web data.
How it works
- You write a prompt on what data you want to extract.
- Kadoa explores the site and finds the most reliable source for the data (e.g. API endpoint, embedded JSON, CSV file)
- It proposes a data structure that you can customize
- It builds the deterministic data pipeline, runs tests, and validates the data
- You review and approve the preview data. You stay in full control.
- The workflow goes live and produces the full dataset, with automated scheduling, notifications, and validations.
Web Scraping OS
The large firms with the big engineering muscles all have their in-house web scraping infrastructure and teams. These are often the central data teams that then manage and maintain all data pipelines for the different teams/pods.
The small- and mid-sized firms usually outsource their web scraping because they don't have the manpower to build and especially maintain a large fleet of pipelines. They often still have a very traditional and slow process going from an internal Jira ticket -> compliance -> data engineer -> web scraping provider -> QA -> dataset.
AI definitely helps with vibe-generating scripts for simple scrapers, but the firms that try to build it all in-house tend to struggle with these challenges:
-
Blocking is an increasing issue (because of the flood of AI bots) and most funds don't have the proxy and unblocking capabilities to keep up with it
-
Scaling web scrapers is really hard because every scrape comes with tech debt and cost of maintaining it. You need to have proper observability, infra monitoring, etc. to handle a lot of scrapes.
-
Compliance usually wants to audit and approve the scrapes, and generally there are no automated processes in place to do that properly
-
With Claude Code, PMs and analysts now start to vibe code their own scraper scripts, which is leading to security, compliance, and data governance issues.
-
Central data teams are actively moving away from siloed data and trying to centralize all data to then give AI access to that.
Our Web Scraping OS deals with all the complexities above and bundles our AI data infrastructure that generates, maintains, and monitors your pipelines automatically, while your central data team keeps control of everything running across every workflow.
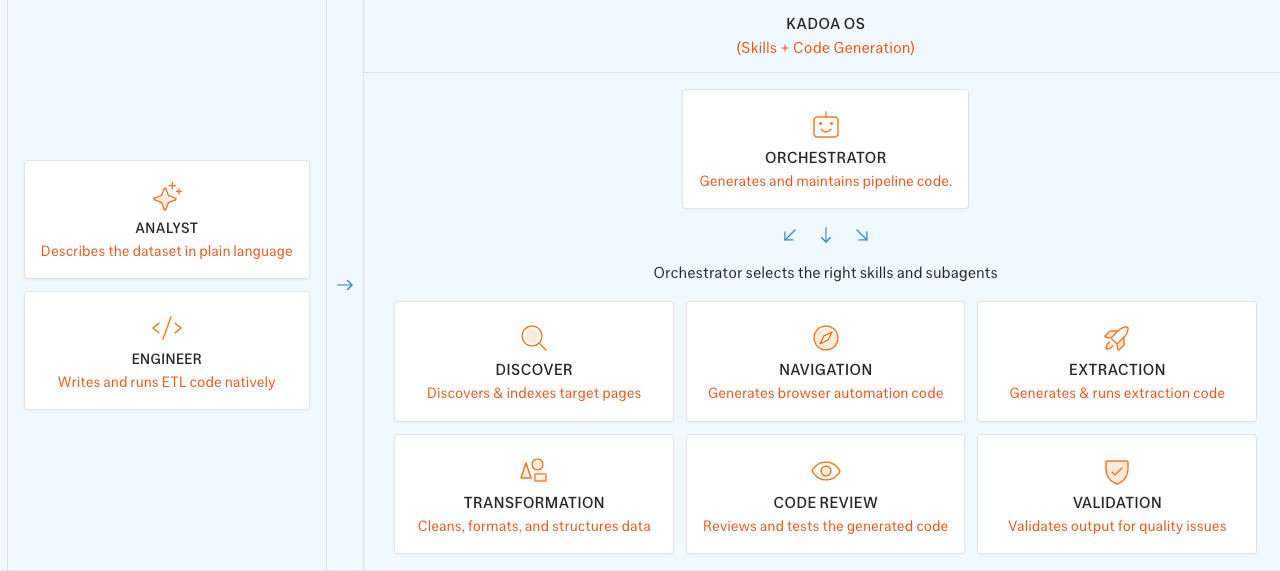
Many teams have a fragmented web data landscape: multiple scraping vendors and tools, the internal engineering time to build and maintain pipelines, and the opportunity cost of the data they never collect because it is too expensive to justify. The Web Scraping OS consolidates it all and becomes the one-stop shop for all web scraping.
Purpose-built for finance
In finance, if data is late, missing, or wrong, somebody feels it (and calls you in the middle of the night). That's why we built a lot of tooling and infrastructure to ensure the highest accuracy and reliability for our customers. All of our data has to be verifiable and auditable while the workflows run on autopilot.
Provably right data and deterministic code
Data used for investment decisions cannot just be "probably correct." LLMs produce probabilistic output that hallucinates and is not verifiable. Kadoa produces deterministic pipelines that generate verifiable data: every value traces back to its source, down to the page it came from. You audit the number, you do not just trust it.

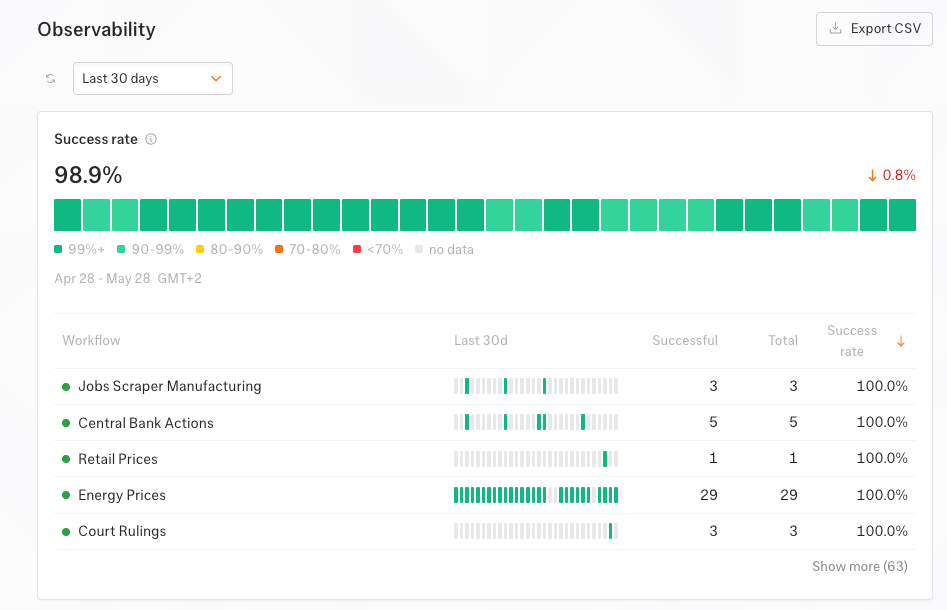
Observability
You see all health metrics of every workflow in one place on our observability dashboard. It includes success rate per source, MTTR, turnaround time, SLA metrics, etc.
Early results
We built this alongside some of the world's most demanding hedge funds and asset managers. Our early-access customers significantly expanded coverage, reduced turnaround and maintenance time, and lowered costs.
Faster to build
- PMs and analysts build datasets on their own, no engineer required
- From investment thesis to data in hours, not weeks
- New multi-source datasets built 5x faster
Reliable at scale
- Cutting maintenance time and MTTR by 80%+
- Reducing false positive data changes by 30%
- Coverage increase with no added headcount
- Compliance review workload down 80% with automated checks
Kadoa Assistant and the Web Scraping OS are available today.
Get in touch to test it for free

Related Articles

From Scrapers to Agents: How AI Is Changing Web Scraping
We spoke with Dan Entrup about how web scraping in finance hasn't evolved much in 20+ years and how AI is changing that now.

The AI Data Stack for Investment Research
How investment firms transform their data stacks to make best use of AI.

Alternative Data for Hedge Funds: A Practical Guide
What hedge funds actually need to build at scale: the signals worth tracking, the pipeline that holds up, and the compliance layer that doesn't block every new source.